what is operative defense?
I have been using a term recently, “operative defense”, and it probably doesn’t reverberate with many people. True, I sort of just made it up one day, but it just came to me as I was trying to describe this thought. So in the effort of trying to clear this up, I wanted to write a short post detailing what I’m describing when I say “operative defense.”
Recently, I was talking with another person who has been in the IT industry for a long time. Now, while she has been a sys admin for probably 25+ years, she hasn’t really focused on the security industry, per se. During our conversation, it dawned on me that - unless one deliberately takes the time to learn sound information security principles - even many seasoned IT pros are not sure what to do to protect their environments. I suspect that this is due, in part, to the fact that security practices and products often times seem like sorcery. Additionally (and this point was made to me directly many times during our conversation), vendors of security products are constantly bombarding IT personnel with such promises of grandeur that IT departments are left mystified and stuck in a state of paralysis by analysis.
So here’s the good part: most of the products being pushed by the vendors are garbage. You don’t need any of them (for the most part). Here’s another bit of good news: if you adopt operative defense, you are going to get your hands dirty and learn a ton. In the process of doing so, you are going to have a better understanding of your environment, and your network and data will be more secure. I suppose that is only good news for those of you who like to roll up your sleeves and get down with your terminal. But anyway, let’s dig in…
First, get back to the basics
In a previous post I described 6 things that your org can do to make it more secure than most. Admittedly, this list was pretty high-level and doesn’t detail precisely how you should accomplish each step. I’ll try to dive into each in more detail in future posts. But for now, just reference that post, and we’ll talk about some of those items here too.
Before you continue implementing your operative defense strategy, you should have the following items down solid:
- Patching. Not only should you make sure you patch all of your systems a minimum of monthly, but also that this is a formal process that includes inventory/asset discovery and reporting.
- Backup and disaster recovery. Make sure your systems are backed up properly, and that you perform test restores on a regular basis.
- NetSec. Audit your firewall rules on a regular basis to ensure you are only exposing ports/services that are absolutely necessary.
- Endpoint. Deploy a solid EDR (endpoint detection and response) tool to your machines. My order of preference is CarbonBlack, Cylance, and then CrowdStrike.
Once you have those boxes checked, move on to implementing a operative defense program.
Operative is the operative word
operative defense is named such because that is precisely what it is. It requires operators. It is operative. It is not a product that you slam in the rack and then, “Boom! You’re secure!” It is a system, with automation, that an operator needs to operate. At a high level and a low level. Daily. It requires attention and thoughtfulness. BUT (and this is a big but) this will make you and your engineers more capable, knowledgeable, and skilled. AND your environment will be more secure because of it.
It’s a trade-off:
- On one hand you could spend thousands of dollars on more GBLs (green blinky lights) that promise to magically make your environment APT-proof. (SPOILER ALERT: They don’t work.)
- Or you could allocate that money to your people. Give them the time, space, training, technology, and skills to operate your environment at a higher level - a more secure level. (SPOILER ALERT: This does work.)
So yeah, either way you are going to spend some money. One path however, will make your engineers more skilled and engaged while also bolstering your security posture; while the other path is really just…well…spending money.
Get your hands dirty
In this section, I want to briefly go into exactly what we’ll be implementing. In subsequent posts, I will detail how to implement each of these items.
Generally, our workflow is going to look something like this:
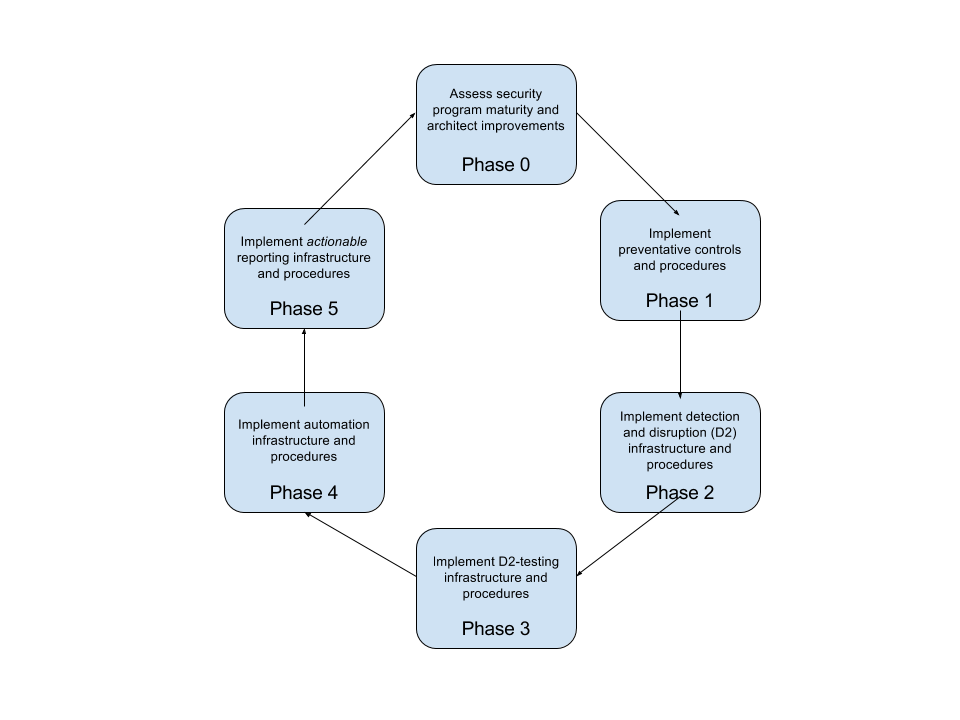
Phase0
I’m big on creating maturity models for security programs. I’ll go into a maturity model in greater detail in another post, but this is really where you should begin when you are designing your security platform. By analyzing where you are in terms of maturity, and where you’d like to be, you can start down the road of architecting what you need to do to attain your target state.
Phase1
When implementing preventative controls and procedures, start with the basics. This will be an iterative process, so you will be able to go back and refine any controls that you need to, once you have gone through the process.
Phase2
This is where things start to get fun. Here you’re going to design and implement your detection and disruption (D2) capabilities. There are multiple tools that you should or could leverage, some commercial but most open source:
- ELK - The Elastic Stack (Elasticsearch, Logstash, and Kibana) is a great place to start. I recommend ingesting logs and events from all of your other tools into your Logstash instance; this will form the foundation of your D2 infrastructure. Get started with Elastic here.
- Splunk - If you have some money to spend, you can use Splunk rather than ELK. I personally don’t have a preference, and have used both; each product is good. Splunk is probably a little easier to get started with, but is more expensive. Get Splunk here.
- Security Onion - For a complete, out of the box network monitoring toolset, build a Security Onion server. You will need a network tap or a trunk and/or span port on your switch. Get Security Onion here.
- Bro - Bro is such a wonderful tool, and comes bundled with Security Onion. Learn this tool; it will give you so much insight into your network. Get Bro here.
- Endpoint such as CarbonBlack, Cylance, or CrowdStrike - This is technically part of Phase1, but good EDR plays an important role in D2 as well.
- Microsoft Sysmon - This tool extends a server’s logging capability and we will be using this as we define our logging and monitoring platform. Read more about Sysmon here.
Phase3
Once we have implemented our D2 infrastructure, you’ll want to put it through the ringer. Here we’ll use some of the common TTPs in our own network to see if our detection capabilities are working.
For example, what happens if we attempt to spray passwords against a DC? Do we get alarms in our D2 infrastructure? What about an internal portscan? Are we detecting that?
See the ATT&CK matrix for a nice list of TTPs to test with. We can also use this matrix to build your detection ruleset.
Phase4
Now we want to automate the testing that we did in Phase3, so it can be repeated easily, often, and in a more efficient manner. After all, continuous testing of our D2 infrastructure is a critical component of operative defense.
For this you can build your own toolset, but I would recommend leveraging projects such as:
- Red Canary’s Atomic Red Team
- MITRE’s CALDERA project
In addition, we will also be automating the deployment of D2 rules, infrastrcuture, and configs. Here you will want to build out your toolset specific to your needs, and I recommend leveraging tools from the DevOps world such as Puppet, Chef, Ansible, Jenkins, and Git.
Phase5
One could argue that automation should come after reporting, and frankly, you won’t get too much argument from me on that. Reporting is critical; more accurately, actionable reporting is critical. You can measure how many portscans your public interface is taking per day, but really who cares? What are you going to do about that anyway? If your infrastructure is reachable from the Internet, then I can tell you right now that you are taking portscans. Regularly.
Rather than report on useless metrics, why not report on how you are getting better at detecting new TTPs within the environment, or how your time to patch vulnerabilities is continuing to shrink, for example.
As I continue to document my operative defense infrastructure, I will include specific reporting details. But to start, you can build reports in Kibana or Splunk.
Conclusion
This post was intended to give a very high-level overview of operative defense, what it is, and how you can take some of these ideas and begin incorporating them into your environment. By doing so you will, if nothing else, learn a whole lot more about your systems and will be better prepared to protect them.
Stay tuned to this blog for additional details around implementing some of these tools and processes.
Credits
Much of what I am promoting in this post has been discussed by other highly-talented, amazing people in our industry. Credit is definitely due to some of these folks (and probably others too):
- Joff Thyer and Derek Banks have some great material here: https://www.blackhillsinfosec.com/endpoint-monitoring-shoestring-budget-webcast-write/
- Chris Nickerson and Chris Gates have talked about this too: https://www.slideshare.net/chrisgates/adversarial-simulation-nickersongates-wild-west-hacking-fest-oct-2017-81444587